UCAS 2024 高级人工智能复习笔记
期末复习资料整理
RuoyuChen10/Study_report: 中国科学院大学研究生课程资料
详细的考题总结:
详细的最后一节课总结+考题:
国科大 高级人工智能 期末复习总结 - yuanninesuns - 博客园
每年的考题类型统计:
国科大 - 高级人工智能(沈华伟等)- 期末复习 - 试卷_国科大高级人工智能期末考试田忌赛马-CSDN博客
2017-2019年的考题:
国科大2017-2019高级人工智能试题以及答案总结_国科大高级人工智能大作业-CSDN博客
2022-2023年的视频和考前总结:
国科大高级人工智能2022-2023罗平老师授课内容笔记 - 知乎
【中国科学院大学】高级AI视频课程_哔哩哔哩_bilibili
GKD_2022_高级人工智能考点总结_哔哩哔哩_bilibili
国科大.高级人工智能.2022期末考试真题回忆版_国科大高级人工智能-CSDN博客
其他还可以瞅瞅的资料:
搜索算法Search开篇_cost-sensitive search-CSDN博客
国科大.高级人工智能.期末复习笔记手稿+复习大纲_国科大 高级人工智能-CSDN博客
国科大高级人工智能博弈论part1-a_哔哩哔哩_bilibili
高级人工智能19-20秋季-中国科学院大学_哔哩哔哩_bilibili
复习范围
- 往年题目
- 往年知识重点总结
- 今年的PPT上的Homework
高级人工智能知识梳理
逻辑
重点内容:命题逻辑(propositional logic)和一阶谓词逻辑
逻辑的重要一张图

模型(Model)、蕴含(Entailment)的基本概念
模型是什么:
model是一个确定的解值
model可以由真值指派来构造

蕴含的定义:

从集合角度看蕴含:

命题逻辑
命题逻辑的语法和语义
命题逻辑的基本性质:
- 与时间无关
原子命题的概念:最小
文字的概念:原子命题、原子命题的非
命题逻辑的BNF定义:

逻辑等价的命题逻辑sentence(都是常用的定理),可以记一下:

(重要)真值指派和truth table:
对于一个知识库KB,其中有N个原子命题,则可以对这N个原子命题进行赋值
这样可以构成turth table,其实truth table就是遍历了所有真值指派的情况构成的
枚举法推导Entailment,以KB entailment α为例:
通过真值指派进行枚举
枚举法复杂度较高


Entailment与implication的区别:

(重要)Sentence的Validity和Satisfiability的概念
可用于证明命题逻辑的归结原理

(重要)两个证明题


例子:Wumpus
一种格子游戏,详情见PPT
例题:奇怪小岛上的逻辑问题
详见PPT,主要掌握:
- 如何将逻辑问题转化为一个形式化的表述,找到变量
- 如何利用规则进行推导:画出真值表格,通过Entailment得出结论
命题逻辑的形式推演
有两套规则,都是可靠且完备的
11条规则的形式推演系统
11条规则



形式可推演性的定义
使用规则进行有限次数的推演

例子:一些证明题,考试可能会考


例子:Wumpus


soundness和completeness的证明:
略过,比较麻烦
Resolution 归结原理(1条规则的形式推演系统)
归结原理的表述
conjunction:合取
disjunction:析取
CNF(conjunction normal form):合取范式
归结原理:互补文字可以互相消去(但是每一次只能消去一对)

任何命题逻辑里的sentence可以在多项式时间内转化为CNF

归结原理的应用:证明KB是否可以推出(或者蕴含)α
这个定理可以用于证明推出(或者蕴含)关系,例如KB推出α(KB蕴含α),这里推出和蕴含两者等价,因为归结原理这个算法是完备的且可靠的
小定理:若KB能归结到空集,则KB推出α,当且仅当{KB,α的非}归结到空集

基于归结原理证明KB蕴含α的算法:
Attention:命题逻辑的归结一定会迎来终止,但是一阶谓词逻辑的归结不一定终止(可能会无限归结下去)

一个例子:

归结原理的完备性和可靠性的证明!(重要)
可靠性(soundness)的证明
比较简单,可以检查truth table,显然有:

完备性(completeness)的证明
前置:
- 定义一个sentence集合的resolution clause:归结闭包(所有可以得到的归结的集合),可以记为$𝑅𝐶(𝑆)$
- 归结闭包是finite的,因为命题逻辑的归结算法一定可以停止
- $S=\left{ KB,\neg\alpha \right}$是unsatisfied的 $\Leftrightarrow $ $KB\wedge \neg \alpha $是unsatisfied的 $\Leftrightarrow $ $KB \models \alpha$(蕴含)
- $𝑅𝐶(𝑆)$中含有空集 $\Leftrightarrow $ $\left{ KB,\neg\alpha \right}$可以归结到空集 $\Leftrightarrow $ $KB\vdash\alpha$(推出)
因此完备性等价于证明(Gound Resolution Theorem):
$S$是unsatisfied的 $\Rightarrow$ $𝑅𝐶(𝑆)$中含有空集 ($S=\left{ KB,\neg\alpha \right}$)

证明思路:
- 证明逆否命题: $𝑅𝐶(𝑆)$中不含有空集 $\Rightarrow$ $S$是satisfied的($S=\left{ KB,\neg\alpha \right}$)
- 反证法,使用有顺序的真值指派构造能够使得$𝑅𝐶(𝑆)$是satisfied的model,则也必使得$S$ satisfied
- $𝑅𝐶(𝑆)$中不含有空集,即没有永假子句
- 只需要考虑本身和本身的否都出现的原子命题(这个讨论其实也可以不需要,直接进行真值指派就行)
- 只出现本身,则指派本身为True
- 只出现否,则指派本身为False
- 按照顺序进行真值指派,其他文字为False时,指派该原子命题(原子命题的否)为True
- 使用反证法证明:这样构造的model可以使得所有子句为True。详见下面
详细证明过程:
第一页这个讨论可以不用


归结原理的实现:Search,A*算法(会考)
如何使用搜索实现归结原理的自动归结过程?
状态:是当前的$RC(S)$
初始状态:$S=\left{ KB,\neg\alpha \right}$
目标状态:包含空集的$RC(S)$
搜索策略:
- BFS:归结所有当前能归结的子句
- DFS
- A*
基于Horn和Definite Clauses的推导、Modus Ponens定理
本质:在归结原理的基础上,给归结的过程加限制,缩小命题逻辑的表达范围,使得时间复杂度降低
Horn Clauses、Definite Clauses的概念
Horn Clauses、Definite Clauses是命题逻辑子句的子集,加了限制
Definite Clauses < Horn 子句 < 命题逻辑子句
- Horn Clauses:正文字的吸取,至少有一个正文字
- Definite Clauses:正文字的吸取,有且只有一个正文字
封闭性:Horn Clauses在Resolution下是封闭的,两个Horn Clauses经过resolution还是Horn Clauses
Horn Clauses的例子:

(重要)Modus Ponens定理(基于Horn Form)
- 适用于Horn Form:所有子句都是Horn Clauses
- 线性时间复杂度
- 相当于进行了n次归结

使用Modus Ponens定理进行归结:前向和后向(需要掌握前后向的流程)
前向归结算法伪代码

前向算法的线性时间是对原子命题的数量线性

具体的前向和后向归结流程图见PPT
前向过程和后向过程的对比
- 前向是data-driven,我有啥=>我能得到啥
- 后向是goal-driven,我目标是啥=>我需要啥
- 对于针对某个目标的推导,后向比前向更加高效,因为前向会推出不需要的结论

可靠性(soundness)的证明
检查truth table,利用truth table可以显然证明:语法上推出的 $\Leftrightarrow $ 语义上蕴含的

完备性(completeness)的证明
这个比resolution的完备性证明简单一点
- $KB \models \alpha$(蕴含)$\Leftrightarrow $ 存在真值指派m使得$KB$和$\alpha$均为True
- $KB\vdash\alpha$(推出)$\Leftrightarrow $ $\alpha\in RC(KB)$
- 即证明:存在真值指派m使得$KB$和$\alpha$均为True $\Rightarrow$ $\alpha\in RC(KB)$
- 构造一种真值指派方式:$a=True $ 当且仅当 $ a\in RC(KB)$
- 通过反证法证明这种指派方式使得KB为True,则$\alpha$也为True(因为$KB \models \alpha$),则$\alpha\in RC(KB)$,$KB\vdash\alpha$
- 反证法分类讨论为False的Horn子句情况,推出矛盾

命题逻辑的总结

命题逻辑的优缺点
缺点:表达能力弱

一阶谓词逻辑
一阶谓词逻辑的语法
基础元素
Object、Relation(输出True or False)、Function(函数映射)


Sentence的定义(BNF)


全称量词


存在量词


一阶谓词逻辑的True和真值指派
和命题逻辑相比:
- 命题逻辑的真值指派:指派原子命题的True or False
- 一阶谓词逻辑的真值指派:指派object的具体是啥

全称量词和存在量词的性质

Equality符号(等于号)的定义

一阶谓词逻辑和命题逻辑的关系(实例化instantiation)
一阶谓词逻辑的实例化(带入object) => 命题逻辑
全称量词的实例化

存在量词的实例化

实例化的例子

一阶谓词逻辑和命题逻辑的形式推演的联系与区别
- 一阶谓词逻辑可以通过实例化来转化为命题逻辑,按照命题逻辑的规则进行推演
- 但是区别:
- 一阶谓词逻辑(FOL)是semidecidable的,即通过归结进行推演不一定会停机
- 原因:由于函数的存在,是可以嵌套的,可以一直产生能归结的子句,不一定停机
- 命题逻辑是decidable的,归结推演最终一定会停机
- 推出了空集
- 没有可以归结的子句
- 一阶谓词逻辑(FOL)是semidecidable的,即通过归结进行推演不一定会停机

FOL转化为命题逻辑进行归结的问题:KB太大了

一阶谓词逻辑的归结原理
合一算子 $\theta$(Unification)的定义(重要)
实际:变量替换,使得 $\alpha$ 和 $\beta$ 相等的变量替换记为 $\theta$ (不一定唯一)
用数学语言表示为:$UNIFY(\alpha,\beta)=\theta\space if\space \alpha\theta=\beta\theta$

归结原理
和命题逻辑的归结相似,但要使用合一算子找到互补文字

一阶谓词逻辑转化为CNF,去掉量词(重要)
技巧:
- 去掉 =>,利用语义等价规则
- 把存在和任意放最外层,这里也用到语义等价规则,否存在=任意否,否任意=存在否
- 对于存在量词:
- 将存在量词标准化:不同的存在是不同的object
- 利用Skolem Function去掉存在量词
- 对于任意量词,直接去掉最外层的任意量词
- 最后,整理为CNF的形式

归结的例子


归结原理soundness和completeness的证明
思路和命题逻辑里相似,但是形式化证明比较复杂,略过
归结策略
最基础的归结策略:广度优先
广度优先归结的特点
优点:
- 完备
- 问题有解时能找到最短归结路径
缺点:
- 浪费时间空间,复杂问题求解时间过长

两大类归结策略:删除和限制
- 删除:删除无用子句,缩小归结的搜索范围
- 限制:添加子句的限制条件
删除:删除单文字
- 单文字定义:子句集合中只含有其正文字的文字
- 单文字不影响子句集合的不可满足性,可以删除

删除:删除重言式
- 重言式永真,不影响子句集合的不可满足性,可以删除

限制:支持集策略(完备)
- 归结的两个亲本至少有一个是目标公式的否定子句或者其后裔
特点:
- 完备的
- 可以视作广度优先归结基础上增加了限制条件
- 限制了子句集合的元素激增,但是增加了归结深度

例子:


限制:单文字子句策略(不完备)
- 归结的两个亲本至少有一个是单文字子句
特点:
- 不完备的,原因:可能没有单文字子句,但是仍能归结出空集

例子:


限制:祖先过滤策略(完备)
- 归结的两个亲本满足:
- 至少有一个是初始子句
- 两个都不是初始子句时,要求一个是另一个子句的父辈
特点:
- 完备的

例子:

重要:一阶谓词逻辑的Modus Ponens定理(GMP)
generalized modus ponens定理

Soundness的证明
去掉全称量词,使用合一算子 $\theta$ 进行证明

Forward Chain和Backward Chain
和命题逻辑的modus ponens的前向、后向相似
具体例子详见PPT
Forward Chain的特点(记忆)
- 可靠的soundness且完备的completeness
- 但是它是semidecidable,即不一定会停机(在FOL definite clause上)
- 原因:function的存在,导致嵌套
- 解决:增加限制条件,使用datalog:没有function的FOL definite clause
Backward Chain的特点(记忆)
- 不完备。incomplete due to infinite loops:
- 解决:check goal against goals on stack,避免循环
- inefficient due to repeated sub-goals:
- 解决:cache previous results,空间换时间

总结

Logic Programming:Prolog
逻辑编程语言的基本概念
给定知识库KB和查询,自动推理出True or False
和普通编程的区别
普通编程的步骤:了解问题-收集条件-寻找解决方法-编程解决-将问题数据化-用程序运行数据-debug
逻辑编程的步骤:了解问题-收集条件-不寻找解决方法-将条件写进KB-将问题转换为fact-问query-寻找错误的事实
Prolog缺点
- 不做occur check,因此有些事实是错的但是也可能推导出来,也就是不sound
- DFS可能造成无穷递归,对的也导不出来,不complete。与语句编写的顺序也有关系
定理自动证明的历史和哥德尔不完全定理(了解)
哥德尔不完全定理粉碎了数学基本公理的幻想
搜索
基于路径的搜索(path-based)
几个例子引入
Romania飞机旅行问题
树上的搜索和图上的搜索
- 图上的搜索:搜索树的叶子节点是visited的节点和unvisited节点的分界点
搜索算法的评价
- 完备性:有解时是否可以得到解
- 算法的时间复杂度
- 算法的空间复杂度
- 是否能找到最优路径(cost最小)
搜索算法的时间和空间复杂度测量
- b:搜索树的最大branch数量
- d:cost最小的解的深度
- m:状态空间的最大深度(可能是无穷大)
无信息的搜索(uninformed search)
BFS(Breadth-First Search)
- 广度优先
- FIFO队列
特点

DFS(Depth-First Search)
- 深度优先
- LIFO队列(就是stack)
特点

Uniform-cost search
- 对比BFS和DFS
- BFS:FIFO
- DFS:LIFO(stack)
- Uniform-cost search:priority queue(优先队列)(least cost out)
- 当每一步的cost都相等时,uniform-cost search退化为BFS
特点:

BFS vs DFS
- BFS:faster,larger memory
- DFS:slower,less memory

Depth-limited search
限制最大深度的DFS
Iterative deepening search(平衡了time和space complexity)
逐步增加最大深度限制的DFS
例子

特点

总结(要记)

有信息的搜索/启发式搜索(informed search)
和无信息搜索相比
在相邻节点选择上,往往选择依据信息进行启发式的选择,而不是依照固定的策略搜索所有相邻节点
三个函数F、G、H的定义
- F(n):起点到终点的经过节点n的路径的距离
- G(n):起点到当前点n的距离(确定值),就是cost
- H(n):当前点n到重点的距离(估计值),使用启发函数估计
- 曼哈顿距离
- 欧拉距离

Greedy Best-first search (贪心搜索)
可以视为A*算法的特殊情况,当g(n)恒等于0的时候,A*就是greedy best-first search
选择距离目标节点直线距离最近的点作为下一个搜索节点
特点
- 不完备

A* Search(重点)
思想
F(n)=G(n)+H(n)
不要扩展F(n)很大的路径,选择F(n)小的路径进行下一步搜索

A*是可接受的启发(admissible heuristic)
- never overestimate the cost
- 设从n到终点的真实cost为$h^*(n)$,则$h(n)\leq h^*(n)$

证明:在tree search上的A*是最优的,由于admissible heuristic(重点)
假设存在一个次优的路径,则次优路径的F永远大于n的F(n是在最优路径上的一个点)
这是由于A*是可接受的启发(admissible heuristic),有$h(n)\leq h^*(n)$

A*是连续的启发(consistent heuristic)
假设有一个点n和点n’,其中n是当前路径上的一个点,n‘是可以由n到达的邻居节点
有:$h(n)\leq c(n,a,n’)+h(n’)$(三角型两边之和大于第三边)
由f=g+h,可推得引理:在A*搜索过程中,$f(n)$的值一定是单调不减的

证明:在graph search上的A*是最优的,由于consistent heuristic(重点)
由于在A*搜索(expend nodes)的过程中,f值是单调不减的,所以第一次搜索到终点的f一定是最小的,即如果一个节点被扩展了多次,那么第一次扩展到该节点的路径的f最小

admissible heuristic和consistent heuristic以及tree search、graph search上optimal的关系
- consistent heuristic一定是admissible heuristic(在h(G)=0的前提条件下)
- admissible heuristic不一定是consistent heuristic,可以举出admissible但不consistent的启发算法

A*的Homework(得看)
参考NUS的homework solution:cs3243-sol03.dvi

consistent => admissible

admissible but not consistent的例子

consistent but not admissible的例子

哪些情况下,A*搜索过 程中,从fringe里面移除的状态总是从初始状态到当前状态的最优路径
在graph search且启发函数是consistent的条件下

一些例子
8-puzzle问题
两种不同的启发函数:
- h1:misplaced tiles
- h2:曼哈顿距离
两者都是admissible的,但是h2比h1更”紧“,h2 dominate h1

admissible的启发函数之间的dominate关系

admissible heuristics对于一个问题的relaxed形式
Admissible heuristics能由原问题的relaxed版本得到
relaxed problem的最优解的cost小于等于原问题的最优解的cost

Homework:使用A*算法设计一种归结原理的搜索策略
迭代改进的搜索(iterative improvement)
和基于路径的搜索不同,对于优化问题,没有明确的起始状态、目标状态和状态转移,只有优化的目标函数,且目标函数难以表达为自变量的解析式,只能给定确定的自变量算出目标函数值,因此适合使用迭代改进的搜索。
基于贪心策略
爬山法:离散
每次贪心的选择当前解x的临近点中value最大的一个作为下一步,逐步需按照极大值点。直到没有更优的邻居,则停止
改进:
- 随机地重启爬山过程:跳出局部最优
- 随机地进行侧移:跳出平坦的地方

梯度下降:连续
沿着导数方向下降
Beam Search
一种 宽度有限的搜索策略,Beam Search 限制了每次扩展节点的数量,只保留最优的 kkk 个候选项(称为“Beam Width”)
介于贪心搜索和广度优先搜索之间的折中方法。它通过限制候选解的数量,减少了搜索空间和计算成本
不能保证全局最优解
基于启发式
模拟退火(SA,simulate annealing)
通过引入“随机扰动”与“接受次优解”的机制,使得算法能够跳出局部最优,从而更有可能找到全局最优解。
核心:随机选择邻域中的一个点作为新解,并且以T的概率接受更差的解。当温度降低到阈值或者到最大迭代次数时停止。
与其他算法对比

演化计算
- 在基因和种群层次上模拟自然界生物进化过程与机制的问题求解技术和计算模型。
- 基于达尔文(Darwin)的进化论和孟德尔(Mendel)的遗传变异理论
- 适者生存,不适者淘汰:自然选择。
- 遗传和变异是决定生物进化的内在因素。(相对稳定+新的物种)
典型代表
- 遗传算法(Genetic Algorithm, GA)
- 进化策略(Evolutionary Strategy, ES)
- 进化规划(Evolutionary Programming, EP)
- 遗传规划(Genetic Programming, GP)
遗传算法(小重点)
重要的是Fitness函数(评价个体的适应度)
遗传算法的基本思想是从初始种群出发,采用优胜劣汰、适者生存的自然法则选择个体,并通过杂交、变异来产生新一代种群,如此逐代进化,直到满足目标为止
基本概念:
- 种群(Population):多个备选解的集合。
- 个体(Individual):种群中的单个元素,通常由一个用于描述其基本遗传结构的数据结构来表示。例如,长度为L的0、1串。
- 适应度(Fitness)函数:用来对种群中各个个体的环境适应性进行度量的函数,函数值是遗传算法实现优胜劣汰的主要依据
- 遗传操作(Genetic Operator):作用于种群而产生新的种群的操作。选择(Selection)、交叉(Cross-over)、变异(Mutation)
流程图

遗传编码
二进制编码
二进制编码是将原问题的结构变换为染色体的位串结构。假设某一参数的取值范围是,,[A,B],A<B。用长度为L的二进制编码串来表示该参数,将,[A,B]等分成2L−1个子部分,记每一个等分的长度为δ
优点:易于理解和实现,可表示的模式数最多
缺点:海明悬崖。当算法从7改进到8时,就必须改变所有的位
格雷编码
要求两个连续整数的编码之间只能有一个码位不同,其余码位都是完全相同的。有效地解决了海明悬崖问题。
基本原理:
- 二进制码->格雷码(编码):从最右边一位起,依次将每一位与左边一位异或,作为对应格雷码该位的值,最左边一位不变;
- 格雷码->二进制码(解码):从左边第二位起,将每位与左边一位解码后的值异或,作为该位解码后的值,最左边一位依然不变。
符号编码
个体染色体编码串中的基因值取自一个无数值含义,而只有代码含义的符号集。
适应度函数
适应度函数是一个用于对个体的适应性进行度量的函数。个体的适应度值越大,它被遗传到下一代种群中的概率越大
原始适应度函数
直接将目标函数作为适应度函数

例:TPS问题

标准适应度函数:要求非负
极小化问题

极大化问题

选择(selection)操作
根据选择概率按某种策略从当前种群中挑选出一定数目的个体,使它们能够有更多的机会被遗传到下一代中
- 比例选择:各个个体被选中的概率与其适应度大小成正比。
- 轮盘赌选择:个体被选中的概率取决于该个体的相对适应度。

交叉(crossover)操作:
按照某种方式对选择的父代个体的染色体的部分基因进行交配重组,从而形成新的个体。
二进制交叉:二进制编码情况下所采用的交叉操作
- 单点交叉:先在两个父代个体的编码串中随机设定一个交叉点,然后对这两个父代个体交叉点前面或后面部分的基因进行交换,并生成子代中的两个新的个体。
- 两点交叉:先在两个父代个体的编码串中随机设定两个交叉点,然后再按这两个交叉点进行部分基因交换,生成子代中的两个新的个体。
- 均匀交叉:先随机生成一个与父串具有相同长度的二进制串(交叉模版),然后再利用该模版对两个父串进行交叉,即将模版中1对应的位进行交换,而0对应的位不交换,依此生成子代中的两个新的个体。
实值交叉:在实数编码情况下所采用的交叉操作,主要包括离散交叉和算术交叉
- 部分离散交叉:先在两个父代个体的编码向量中随机选择一部分分量,然后对这部分分量进行交换,生成子代中的两个新的个体。
- 整体交叉:对两个父代个体的编码向量中的所有分量,都以12的概率进行交换,从而生成子代中的两个新的个体。
变异(Mutation)操作:
对选中个体的染色体中的某些基因进行变动,以形成新的个体。遗传算法中的变异操作增加了算法的局部随机搜索能力,从而可以维持种群的多样性。
二进制变异:
- 先随机地产生一个变异位,然后将该变异位置上的基因值由“0”变为“1”,或由“1”变为“0”,产生一个新的个体。
实值变异:
- 用另外一个在规定范围内的随机实数去替换原变异位置上的基因值,产生一个新的个体。
- 基于次序的变异:先随机地产生两个变异位置,然后交换这两个变异位置上的基因。
精英主义 (Elitism)
在每一次产生新的一代时,我们首先把当前最优解原封不动的复制到新的一代中,其他步骤不变。这样任何时刻产生的一个最优解都可以存活到遗传算法结束。
遗传算法特点
自组织、自适应和自学习性—概率转移准则,非确定性规则
- 确定进化方案后,算法将利用进化过程中得到的信息自行组织搜索;基于自然的选择策略,优胜劣汰;
- 遗传算法很快就能找到良好的解,即使是在很复杂的解空间中
- 采用随机方法进行最优解搜索,选择体现了向最优解迫近
- 交叉体现了最优解的产生,变异体现了全局最优解的复盖
本质并行性—群体搜索
- 算法本身非常适合大规模并行,各种群分别独立进化,不需要相互间交换信息
- 可以同时搜索解空间的多个区域并相互间交流信息,使得演化计算能以较少的计算获得较大的收益。
不需要其他知识,只需要影响搜索方向的目标函数和相应的适应度函数
- 对待求解问题的指标函数没有什么特殊的要求,如不要求连续性、导数存在、单峰值等假设
- 容易形成通用算法程序
- 遗传算法不能解决那些“大海捞针”的问题,所谓“大海捞针”问题就是没有一个确切的适应度函数表征个体好坏的问题,遗传算法对这类问题无法找到收敛的路径。
理论上证明算法的收敛性很困难
多用于解决实际问题
例子:8皇后问题
例子:求f(x)=x^2在[0,30]上的最大值
对抗搜索(adversarial)
例子:井字棋、国际象棋
两个Player的博弈
两个palyer的博弈是零和博弈,multi-player的博弈则不一定是零和博弈
博弈树(Game Tree):
- 博弈问题可以建模为一个树结构,根节点表示当前的游戏状态,分支表示所有可能的行动。
- 每个节点的轮到谁行动(“自己”或“对手”)会交替发生。
目标:
- 玩家 A(通常称为“自己”)希望最大化其收益。
- 玩家 B(对手)则希望最大化自己的收益,即最小化玩家 A 的收益。
- 总收益为零,因此是零和博弈。
评价函数(Evaluation Function):
- 在博弈树的叶子节点或某些中间节点处,使用评价函数评估当前状态的“好坏”(对当前玩家有利或不利的程度)。
Minimax search(最大最小搜索)
Minimax 是对抗搜索的基本算法,它沿着博弈树进行搜索,假设对手总是做出对自己最不利的选择。
在自己的回合,选择使得收益最大的操作(Max)。
在对手的回合,假设对手会选择使得收益最小的操作(Min)。

特点:

Alpha-Beta Pruning(α-β剪枝)
Alpha-Beta 剪枝是 Minimax 算法的优化版本,通过剪枝减少了需要搜索的节点数量。
核心思想:
如果在某个节点已经发现更优的路径,则不需要探索那些不可能影响最终决策的子树。
用两个变量 α 和 β 来记录当前节点的可接受范围:
- α:当前路径中“Max”的最低可能值。
- β:当前路径中“Min”的最高可能值。
注意:剪枝并不保证最终解的质量

特点:


Expect-Minimax(带期望的最大最小搜索)
适用于 带有随机性因素的博弈或问题。它结合了对抗搜索(Minimax)的决策思想和概率的数学期望,用于处理决策中既有对手行动,也有随机事件影响的情形。在Minimax基础上增加了Chance节点。
对于 Chance 节点 ,其期望值计算如下:
$$
\text{ExpectedValue} = \sum_{i=1}^{n} P_i \cdot V_i
$$
$$P_i$$:第 $$i$$ 个可能事件发生的概率。
$$V_i$$:第 $$i$$ 个可能事件对应的子节点得分。

Monte Carlo simulation(蒙特卡洛模拟)辅助计算chance节点
通常不使用剪枝(因为低效)
部分观测下的Nash Equilibrium(纳什均衡)

总结(重要)
- MiniMax 搜索用于零和双人博弈,并且信息完全透明。
- Alpha-Beta 剪枝能够让搜索更加深入。
- 由于资源限制,通常使用启发式方法来评估一个状态的“好坏”。
- 对于随机性博弈,需要引入概率节点并搜索期望最大值或最小值(Expect-MiniMax)。
- 在随机性博弈中,剪枝效率显著降低,因此常常使用蒙特卡洛模拟。
- 在部分观测的情况下,“最优性”通常难以明确定义。如果存在平衡点,处于平衡的策略通常被认为是最优的。

联结主义
监督学习
- 回归问题:标签为连续值
- 分类问题:标签为离散值

标签学习、单变量学习
分类回归思想
决策树(输出是离散值、分类问题、最小化条件信息熵)
信息熵(香浓信息熵 Shannon Entropy)
熵有很多的定义,但是常说的信息熵是指香浓信息熵H(Y)

条件信息熵
含义:在条件X下需要预测的Y的信息熵,H(Y|X)
公式定义: $$H(Y|X) = \sum_{i} P(x_i) H(Y|X=x_i)$$
其中, $$H(Y|X=x_i) = -\sum_{y_j} P(y_j|x_i) \log P(y_j|x_i)$$
信息增益(information gain)
度量条件X对Y的预测能力
Gain(X,Y)=H(Y)-H(Y|X)

决策树的构建
选择节点的特征,使用贪心算法
贪心算法:最大化信息增益<=>最小化条件信息熵
停止条件:节点内样本的信息熵小于一定的阈值
回归树(输出是连续值、回归问题、最小化回归误差)
监督学习模型的要素之一:目标函数
回归树建立目标函数的要求:
- 在训练数据上,预测尽量准确
- 树的结构简单
- 叶节点的数量小
- 叶节点对应的预测值的绝对值小
目标函数的整理过程:(需要看一眼)

韦达定理给出使得目标函数最小的$w_j$的值

总结:回归树的目标函数包含两部分
- 平方误差衡量预测值与真实值的差距。
- 正则化项控制模型复杂度,避免过拟合。
监督学习模型的要素之一:优化过程——贪心算法
分裂点的选择准则是最大化 目标函数的减小量,使得目标函数尽可能地下降。
假设将某个叶节点分裂为左右两个子节点:
- 未分裂前目标函数为:
$$
-\frac{2B^2}{2A + \lambda} + \gamma
$$
- 分裂后目标函数为:
$$
-\frac{2B_L^2}{2A_L + \lambda} - \frac{2B_R^2}{2A_R + \lambda} + 2\gamma
$$
- 分裂的目标函数减少量为:
$$
\text{Gain} = \frac{B_L^2}{A_L + \lambda} + \frac{B_R^2}{A_R + \lambda} - \frac{B^2}{A + \lambda} - \gamma
$$
每一步优化的问题:找到最佳切分的点

监督学习模型的要素之一:模型预测
给定新样本,最终落入的叶节点的值为预测值
渐进梯度回归森林(GBRT)
都是工业界常用的分类器和回归器
GBRT:Gradient Boosting Regression Trees
GBDT:Gradient Boosting Decision Trees
GBRT 是一种加性模型(Additive Model),它通过构建多个回归树的线性组合来近似目标函数。目标是在每一轮迭代中优化模型,使得预测值逐步逼近真实值。
Additive Ensemble(加性模型)
即综合多个树的预测结果,将预测值相加

监督学习模型的要素之一:目标函数
假设有k棵树,则GBRT可以形式化表示为$ \hat{y}i = \sum{k=1}^K f_k(x_i) $
优化目标要求:
- 训练误差小(均方误差等)
- 模型复杂度低

监督学习模型的要素之二:优化过程
每一轮新增一棵树,用来拟合残差。
使用贪心算法选择分裂点和优化叶节点预测值。
贪心算法:考虑逐步添加树的过程

考虑第t轮添加树的情况


和回归树的目标函数优化对比
GBRT主要是$B_j$的值不一样,是真实值减去前t-1个树的预测值的线性和
对于第t个树的动态生成过程
分裂点的选择准则是最大化 目标函数的减小量,使得目标函数尽可能地下降。

监督学习模型的要素之三:模型预测
即$ \hat{y}i = \sum{k=1}^K f_k(x_i) $,所有树的预测值的线性和
概率思想
Logistic Regression(最大化数据似然)
Logistic Regression是一种基于最大化似然函数的线性分类器,用于二分类
Logistic 回归的参数是一个向量 $\theta$,它描述了每个特征对输出概率的贡献。
参数的优化通过最大化对数似然(或最小化 负对数)实现,常用梯度下降算法。
在实际应用中,可能加入正则化项,对参数 $\theta$ 添加约束以提高模型的泛化能力。
一、优化目标的建立
常用sigmoid函数作为特征值到概率的映射函数

优化概率似然函数:最大化概率似然函数<=>最小化其负对数

二、优化参数、训练过程
- 梯度下降的方法进行预测
- 使用minibatch进行梯度下降


三、模型进行预测
sigmoid:二分类,使用概率最大的哪个类别作为预测值

和线性回归对比
- 损失函数不一样
- 线性回归:均方损失
- LR:概率似然函数
- 分类平面
- 线性回归:$\theta^T x+\theta_0=0.5$。本质上是为回归问题设计的,不适合直接用于分类任务。即使能通过设定阈值实现分类,其分类平面缺乏合理性和概率解释。
- Logistic 回归:$\theta^T x+\theta_0=0$。通过 Sigmoid 函数实现概率建模,适用于分类任务,分类平面由概率阈值确定,表现更加鲁棒且结果易于解释。
- 都是线性分类器
- Logistic Regression对异常点更加鲁棒

对Logistic Loss的理解
二分类的损失

模型的正则化方法
在代价函数中考虑权重θ自身带来的影响,避免权重太多太大,造成过拟合
- L1正则化
- L2正则化
Homework:除了sigmoid函数,还有什么函数可以建模概率?
softmax函数:多分类问题(而非二分类问题),广泛用于神经网络中的分类问题。
集成的方法
Bagging
- Bagging 是一种基于 自助采样法(Bootstrap Sampling) 的集成学习方法,通过对多个基模型(弱学习器)进行训练,并对它们的预测结果进行平均或投票,来提升模型的稳定性和精度。它适用于分类和回归任务。
- 袋外数据(OOB)的概念:假设有N个样本,针对某个样本,有放回的抽N次没被抽到的概率为$(1-\frac{1}{N} )^N$,当N很大时,有$\lim_{N \to \infty} (1-\frac{1}{N} )^N=\frac{1}{e}=0.3679$。因此子数据集中可能包含重复样本,而原始数据集的某些样本可能未被采样(通常约 1/31/31/3 的样本未被选中,用作袋外数据(OOB,Out-of-Bag))。

Random Forest
Random Forest就是基于Bagging的一种集成学习方法。
与 Bagging 的区别: 随机森林在 Bagging 的基础上增加了特征随机性,使得每棵树的训练更加多样化,从而进一步降低方差,提高模型的泛化能力。

Adaboost
AdaBoost 是一种基于弱分类器加权组合的集成学习算法。
算法步骤
算法步骤 假设我们有训练数据集 $${(x_1, y_1), (x_2, y_2), \dots, (x_N, y_N)}$$,其中 $$y_i \in {-1, 1}$$ 表示类别标签。
1.初始化样本权重:
给每个样本分配初始权重:即样本权重均匀分布。
$$
w_i^{(1)} = \frac{1}{N}, \quad i = 1, 2, \dots, N
2. 迭代训练弱分类器:
$$
2.迭代优化:
对于每一轮 $$t = 1, 2, \dots, T$$:
训练弱分类器:
- 使用当前样本权重 $$w_i^{(t)}$$ 训练弱分类器 $$h_t(x)$$。
计算分类误差:
- 计算弱分类器在当前权重分布下的分类误差:其中 $$\mathbb{I}(\cdot)$$ 是指示函数,分类错误时为 1。
$$
\epsilon_t = \frac{\sum_{i=1}^N w_i^{(t)} \mathbb{I}(h_t(x_i) \neq y_i)}{\sum_{i=1}^N w_i^{(t)}}
$$
- 计算弱分类器在当前权重分布下的分类误差:其中 $$\mathbb{I}(\cdot)$$ 是指示函数,分类错误时为 1。
计算弱分类器权重:
- 根据分类误差计算弱分类器的权重 $$\alpha_t$$,$$\alpha_t$$ 越大,表示弱分类器的分类能力越强。
$$
\alpha_t = \frac{1}{2} \ln \left(\frac{1 - \epsilon_t}{\epsilon_t}\right)
$$
- 根据分类误差计算弱分类器的权重 $$\alpha_t$$,$$\alpha_t$$ 越大,表示弱分类器的分类能力越强。
更新样本权重:
增大分类错误样本的权重,减小分类正确样本的权重:
$$
w_i^{(t+1)} = w_i^{(t)} \cdot \exp\big(-\alpha_t y_i h_t(x_i)\big)
$$然后对权重进行归一化
$$
w_i^{(t+1)} = \frac{w_i^{(t+1)}}{\sum_{i=1}^N w_i^{(t+1)}}
$$
3.最终强分类器:
将所有弱分类器按其权重组合成强分类器:
$$
H(x) = \text{sign} \left( \sum_{t=1}^T \alpha_t h_t(x) \right)
$$
Homework证明题(得看):证明AdaBoost算法训练误差的上届
AdaBoost算法(二)——理论推导篇_adabosast-CSDN博客

机器学习解决实际问题
- 参数不是越多越好。参数过多容易过拟合,需要使用正则化手段避免
- 常用方法:决策树,GBDT(Gradient Boosting Decision Tree)+线性回归(LG)
前馈神经网络
神经元的概念
$h_{w,b}=f(w^Tx+b)$

两类问题:分类和回归,及其目标函数
分类问题
- logistic(sigmoid),单分类
- softmax函数,多分类
- 目标函数的形式

回归问题
- 例如回归一个(x,y)
- 目标函数的形式

优化方法:BP(重要)
本质:仍然是用梯度下降进行优化。
BP的推导基础
- 复合函数求导
- 链式法则
BP算法训练FFN的大致过程
- 第一步,初始化网络权重和各项参数
- 第二步,从训练集选取样本
- 第三步,前向传播,计算各层的输出,以及损失函数
- 第四步,反向传播
- 反向传播逐层计算损失函数$Loss\space Funciton=C$对各层的输入的$z^l$的误差$\delta^l=\frac{\partial C}{\partial z^l}$
- 通过链式法则和复合函数求导规则,逐层计算
- 通过$\delta^l$和$\frac{\partial C}{\partial w^l}$、$\frac{\partial C}{\partial b^l}$的关系计算每层的w和b的梯度
- 反向传播逐层计算损失函数$Loss\space Funciton=C$对各层的输入的$z^l$的误差$\delta^l=\frac{\partial C}{\partial z^l}$
- 第五步,梯度下降更新网络权重
- $w^l=w^l-\eta\frac{\partial C}{\partial w^l}$
$b^l=b^l-\eta\frac{\partial C}{\partial b^l}$
- $w^l=w^l-\eta\frac{\partial C}{\partial w^l}$
- 第六步,检查训练是否可以停止
- 如果到了指定轮次或者loss下降到指定阈值则停止
- 否则回到第二步
BP的问题:梯度消失和梯度爆炸
当网络变深时,BP算法会遇到梯度消失或者梯度爆炸的现象,此时浅层的神经元几乎接受不到来自输出层的误差信号或者误差太大,无法更新其参数或参数剧烈波动。
梯度消失的原因
根据链式求导法则,浅层参数的梯度来源于深层参数梯度的乘积。由于中间梯度矩阵的范数可能远小于1,再加上许多激活函数的导数小于1,随着传播层数的增多,误差信号反向传播的过程中以指数形式衰减,当传播到浅层时便出现了梯度消失现象。
梯度爆炸的原因
在反向传播中,梯度是通过链式法则从输出层向输入层逐层传递的。如果网络中某一层的权重矩阵的元素非常大,或激活函数的导数较大,那么梯度的值会随着层数的增加而逐渐变大。这样,后面层的梯度会被逐步放大,最终导致梯度值异常大,这就是“梯度爆炸”。
特别是在深层神经网络中,随着反向传播层数的增加,梯度在各层间传递时可能会被不断放大,从而导致最终的梯度值异常大。
训练的使用技巧
数据块的选择
- batch training
- SGD
- miniBatch

激活函数
- sigmoid(logistic)
- tanh
- softsign
- ReLU
- Leak ReLU
- Randomized Leak ReLU

正则化
- 损失函数中引入正则化项
- Dropout

学习率调节
- 预设learning rate
- 参考验证集调节
- 指数衰减
- AdaDELTA、RMSProp

Backprop(重要)
两个法则
- 链式法则
- 多元函数求导法则
计算图的概念

画计算图
链式法则计算图
多元函数求导计算图
FFN计算图
在计算图上求解
卷积神经网络
卷积神经网络的设计理念
- 局部性连接
- 权值共享(卷积核)
- 空间降采样

卷积神经网络的基本结构
- 卷积层
- 卷积核
- 卷积操作怎么算的
- Padding
- Stride
- 卷积核
- Pooling层
- Max Pooling
- Mean Pooling
- Pooling的意义:
- 减少参数,降低模型复杂度
- 获得对局部微小平移、缩放的不变性
- 激活函数
- Sigmoid
- tanh
CNN模型的case
AlexNet
- data augmentation、dropout、ReLU
GoogleLeNet
- 级联inception块
- 完全去除全连接层
- 中间层加入辅助损失函数,改善深度增加导致的梯度消失
循环神经网络
RNN的基本介绍
RNN可以做什么
对序列进行建模,是一个seq2seq的神经网络
可以解决序列标注、翻译等问题
RNN的模型结构的形式化建模

RNN的特点
- $h_i=f(x_i,h_{i-1})$ 每个时刻的输出是上一时刻的输出和当前时刻的输入的函数
- 所有时刻的数据共享一组神经元参数
RNN的研究关键点
RNN, LSTM, GRU模型的作用, 构建, 优劣势比较,attention机制_gru的特点和优势-CSDN博客
- 研究函数f如何建模
- LSTM
- GRU
- 研究$x_i$如何表示,embedding如何表示,word2vector
LSTM(一种RNN的f建模方式)
- 输入门
- 输出门
- 遗忘门

GRU(一种RNN的f建模方式)
- 重置门
- 更新门

RNN做翻译任务(重要)
神经机器翻译(seq2seq RNN)实现详解 - Django’s blog - 博客园
- encoder-decoder结构,encoder和decoder都是RNN
- 建模P(目标语句|原语句)
- 可以端到端训练
- 可以构建多层2网络
- 初始状态设置为0向量
- 损失函数:每个词的预测的损失相加

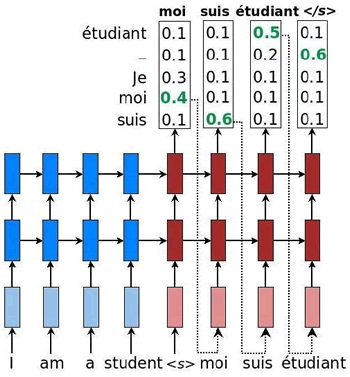
注意力机制
朴素RNN出现的问题:
- 只能保留最后处理的单词的信息
- 对于长句子,会遗忘掉源句早期处理单词的信息
解决:提出了一种注意力机制(非我们现在的注意力)


图卷积神经网络
回顾CNN的成功
在欧几里得空间上的局部性和平移不变性->卷积核很有用,卷积操作有用
但是,如果是非欧氏空间呢:从CNN->Graph CNN
图像:欧氏空间、网格状
图:不规则的空间
回顾卷积
卷积是两个函数之间的一种运算
- 连续的卷积
- 离散的卷积
定义图上的卷积
谱方法:在谱空间中定义卷积
空间方法:在向量空间中定义卷积
- 卷积被定义为目标结点到它的所有邻居的一个加权平均函数
- 主要挑战是邻域的大小在结点之间差异很大,可能服从幂律分布
谱方法是空间方法的特例
- 谱方法通过特别的空间变换定义核函数
- 空间方法直接定义核函数
Spectral methods(谱方法)
基于图的谱理论,利用拉普拉斯矩阵的特征分解定义卷积操作,但计算代价高且局部性不足。
具体步骤:
- 图的拉普拉斯矩阵 :
给定图 $$G = (V, E, W)$$,其中 $$V$$ 是节点集,$$E$$ 是边集,$$W$$ 是加权邻接矩阵。
图的标准拉普拉斯矩阵 $$L$$ 定义为 $$L = D - W$$,其中 $$D$$ 是度矩阵。
或者使用归一化拉普拉斯矩阵 $$L_{norm} = I - D^{-1/2} W D^{-1/2}$$。
- 谱域变换 :
- 对拉普拉斯矩阵 $$L$$ 进行特征分解:
$$
L = U \Lambda U^T
$$
其中 $$U$$ 是特征向量矩阵,$$\Lambda$$ 是特征值对角矩阵。
- 图信号 $$x$$ 的谱域表示为 $$\hat{x} = U^T x$$。
- 卷积操作 :
- 利用卷积定理,将两个信号在谱域的卷积转换为点乘:
$$
x \ast_G y = U g_\theta(\Lambda) U^T x
$$
其中 $$g_\theta(\Lambda)$$ 是卷积滤波器。
优点和缺点:
优点 :
- 使用全局的图谱信息,理论性强。
缺点 :
需要对拉普拉斯矩阵进行特征分解,计算复杂度高(约为 $$O(n^3)$$)。
卷积核定义在谱域中,不局限于局部节点,导致不容易在顶点域中实现局部化。
ChebyNet
一种基于谱方法的图神经网络,它通过使用 Chebyshev 多项式 来近似图的卷积操作,从而解决了传统谱方法(如 Spectral CNN)中计算复杂度高的问题。
Graph Wavelet Neural Network(GWNN)
谱方法的改进,基于小波变换,通过替换 Fourier 基底为 Wavelet 基底,实现更好的局部化、稀疏性和计算效率。为了解决传统谱方法的计算复杂度和局部化问题,同时提升在大规模图上的实际应用能力。
Spatial Methodes(空间方法)
不同于 Spectral Methods 基于谱域的定义和操作,Spatial Methods 直接在图的顶点域(vertex domain)上定义卷积操作,注重从节点的局部邻域中聚合信息。
1. Spatial Methods 的核心思想
- 局部化操作:
Spatial Methods 直接在图的拓扑结构上进行计算,而不需要谱方法中的拉普拉斯矩阵特征分解。
在每个节点,卷积操作通过从其邻域节点中聚合信息来更新节点的表示。
- 邻域聚合:
- 对于每个节点 $$v$$,其特征表示 $$h_v$$ 的更新依赖于自身的特征 $$h_v$$ 和其邻域节点的特征 $$h_u, \forall u \in \mathcal{N}(v)$$:
$$
h_v^{(t+1)} = \text{Aggregate}({ h_v^{(t)}, h_u^{(t)} | u \in \mathcal{N}(v) })
$$
- Aggregate 是一个聚合函数,如平均值、求和或最大值等。
- 迭代更新:
- 通过多次聚合操作,信息逐步从邻域扩散到更大的范围,实现更深层次的图结构表示学习。
行为主义
群体智能
蚁群算法:离散解空间
蚁群算法是一种用来寻找优化路径的概率型算法。
- 用蚂蚁的行走路径表示待优化问题的可行解,整个蚂蚁群体的所有路径构成待优化问题的解空间。
- 路径较短的蚂蚁释放的信息素量较多,随着时间的推进,较短的路径上累积的信息素浓度逐渐增高,选择该路径的蚂蚁个数也愈来愈多。
- 最终,整个蚂蚁会在正反馈的作用下集中到最佳的路径上,此时对应的便是待优化问题的最优解。
蚁群优化算法的形式化
- 一个蚂蚁对应一个智能体
- 蚂蚁依照概率选择候选位置进行移动
- 在经过的路径上留下信息素
- 信息素随着时间挥发
- 信息素浓度大的路径选择的概率更高

蚁群算法求解旅行商问题(TSP)
问题定义

时刻t,蚂蚁k从i运动到j的建模

i到j的路径上的信息素的更新建模

算法伪代码

小结
- 优点
- 局部搜索+自增强
- 缺点
- 不一定能收敛到全局最优解
- 收敛速度慢
- 不能用于连续解空间的问题
粒子群算法:连续解空间

形式化定义
- 粒子群
- 记录
- 适应函数

算法流程
初始化
循环更新
速度更新公式的解读
- 惯性项:保持原速度
- 记忆项:向着自己的最好位置
- 社会项:向着群体的最好位置


Homework:用粒子群算法求解函数极值
强化学习
强化学习基本概念
目标:学习从环境状态到行为的映射(即策略),智能体选择能够获得环境最大奖赏的行为,使得外部环境对学习系统在某种意义下的评价为最佳
和监督学习的区别
- 监督学习:从标注中学习
- 强化学习:从交互中学习
强化学习的要素
- 主体:智能体和环境
- 交互:状态、行为、奖励
- 策略:状态到行为的函数,确定或者随机
- 奖励:关于状态和行为的函数,通常有随机性
- 价值:累计的奖励、长期的目标
- 环境模型:刻画环境对行为的反馈

多臂赌博机
一台赌博机有多个摇臂,每个摇臂摇出的奖励大小不确定,玩家希望摇固定次数的臂所获得的期望累积奖励最大
优化目标:期望累计奖励最大化
贪心策略:完全贪心
利用和探索
利用:完全贪心,最大化即时奖励
探索:不完全贪心,短时奖励较低,长期奖励可能更高
如何平衡“利用”和“探索”是关键
$\varepsilon$-贪心策略:不完全贪心
- 以$\varepsilon$的概率在所有行为中随机选一个(探索)
- 以$1-\varepsilon$的概率按照贪心策略选择行为(利用)
乐观初值法:打一枪换一个地方
未发生之前,保持乐观的心态。每次摇完臂都会失望,所以下次会换个臂摇,鼓励探索。
UCB行为选择策略
对Qt(a)做估计,但因为估不准(估不准与之前尝试的次数有关,尝试次数越多估的越准),所以对它做一个上界。
次数够多,UCB会接近贪心策略。
梯度赌博机算法
和前面的都不同,这是一个随机策略
对比
UCB策略表现相对较好
马尔科夫决策过程
行为不仅获得即时奖励,还能改变状态,从而影响长期奖励
- 智能体(Agent)和环境(Environment)按照离散的时间步进行交互
- 智能体的状态S、智能体采取的行为A、获得的奖励R
- 奖励假设:最终目标是通过最大化累积的Reward实现的

贝尔曼最优性方程
状态估值和行为估值的贝尔曼最优性方程



实际应用中的策略学习
动态规划
策略迭代:从初始策略开始,迭代进行策略估值和策略提升,最终得到最优策略
- 策略估值:解给定的策略下的值函数,也就是预测当前策略下所能拿到的值函数问题。
- 策略提升:根据当前策略的估值函数,寻找更优的策略(如果存在)
估值迭代:值迭代算法是策略评估过程只进行一次迭代的策略迭代算法,从初始状态估值开始,进行估值迭代,找到最优状态估值,按照贪心方式得到最优策略
从运算量角度看,值迭代方法中策略评估只需要一次迭代,需要的运算量更小,应该比策略迭代更快收敛。但是,通常在策略提升中间插入需要多次迭代的策略评估的算法,收敛的更快!这可能与值迭代算法的终止条件有关。值迭代算法的终止条件对象为值函数,策略迭代算法的终止条件对象为策略,结合之前gridworld中观察的现象(策略可能比值函数收敛的更快),所以策略迭代可能比值迭代更快收敛。
蒙特卡洛:(通过采样的方式,最后用样本的平均值作估值,是一种从经验中获得的方法)
- 从真实或者模拟的经验中计算状态(行动估值函数)不需要关于环境的完整模型
- 直接根据真实经验或模拟经验计算状态估值函数
- 不同状态的估值在计算时是独立的,不依赖于“自举”方法
时序差分:非平稳情形下的蒙特卡洛方法(恒定步长)
参数近似

博弈
纳什均衡
如果一个局势下,每个局中人的策略都是相对其他局中人当前策略的最佳应对,则称该局势是一个纳什均衡(单独一个人更改策略会损害其他人的利益)
- 任何有限状态的博弈都至少存在一个纳什均衡
- 不一定是纯策略的那是均衡,可能是混合纳什均衡(剪刀石头布)
田忌赛马
囚徒困境
帕累托最优
对于一组策略选择(局势)若不存在其他策略选择使所有参与者得到至少和目前一样高的回报,且至少一个参与者会得到严格较高的回报,则这组策略选择为帕累托最优。(“不可能再改善某些人的境况,而不使任何其他人受损。”)
社会最优
- 使参与者的回报之和最大的策略选择(局势)
- 社会最优的结果一定也是帕累托最优的结果
- 帕累托最优不一定是社会最优
应用
拍卖
- 首价密封报价拍卖
- 纳什均衡:每个竞拍者的报价低于其对商品的估价
- 最优报价低于估价,竞拍者越多,报价越接近于估价
- 次价密封报价拍卖
- 纳什均衡:每个竞拍者会倾向于采用其对商品的估价进行报价
讨价
讨价的对象是双方对商品估价之差
海盗分金币
MaxMin和MinMax
maxmin策略:最大化自己最坏情况时的效用
- 最小化损失,控制风险
- 预防其它局中人的不理性给自己带来损失
minmax策略:最小化对手的最大效用
零和博弈情况下:
- minmax和maxmin是对偶的
- minmax策略和maxmin策略等价于纳什均衡策略
匹配问题
中介市场
议价权
因果推断
阻断、d-分离
后门路径
例题
- C

- B
- 正确:
Prolog 实现了一个既不可靠又不完备的形式推演系统